Introduction
My career has been defined by curiosity. I always like learning something new and have often taken the opportunity to substantially change my career direction when the opportunity to work on something completely different presented itself. I graduated with a degree focused on embedded systems, but found my first job in enterprise Java development. From there, I moved on to rich web clients, followed by what's now called full-stack development. Now, for several years, I have been focused on on backend services, machine learning and people management.
I've had a lot of cool experiences in my career. Some of the things I'm proud of: I recently hired over twenty people for my team inside of a year in a single rocket-ship of a project. I've owned the engineering for two different AWS service launches. I've co-authored a paper accepted in a major conference. I have several patent submissions (one granted so far). I've started a company. I've joined a startup as it was taking off. Currently I'm learning more about healthcare in the United States by working with a large non-profit healthcare system.
Projects
QuickSight Q: Zero to Public Preview
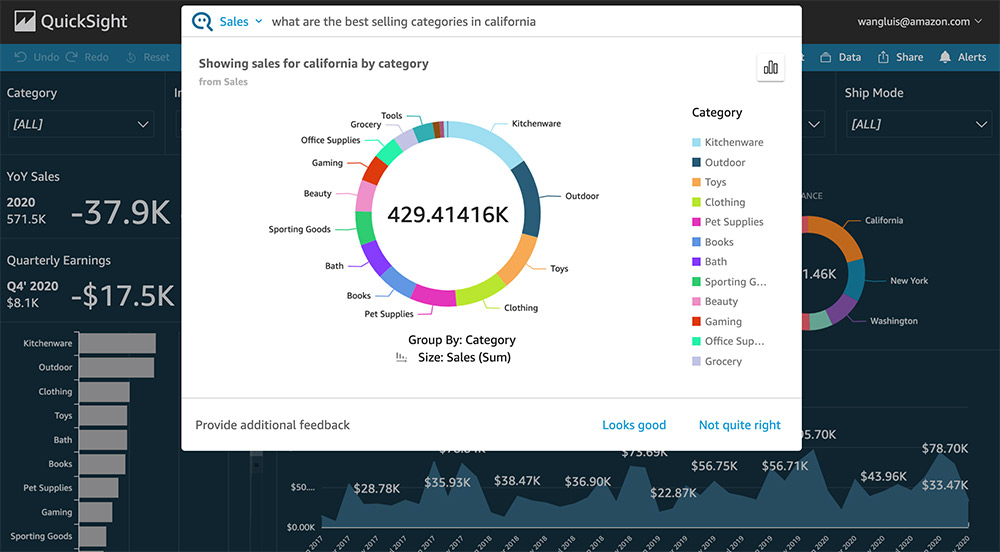
As the first engineering manager for QuickSight Q, I led the development of the AWS QuickSight Q service from its inception through its public preview. Working closely with a talented product development and machine-learning science team, we built the team and the project at the same time. The engineering org that I owned grew to three teams within the year and encompassed teams devoted to service development, data pipeline tooling, and an ML team focused on knowledge discovery and data mining.
QuickSight Q was a tremendously successful project that married extremely rapid development with cutting edge machine learning research. The combination of tight deadlines and rapid scientific experimentation is incredibly challenging and most teams that attempt it don't manage it. I was very proud to contribute to a team that took such an ambitious concept and executed on it so well and so rapidly.
Glue ML: Zero to Generally Available
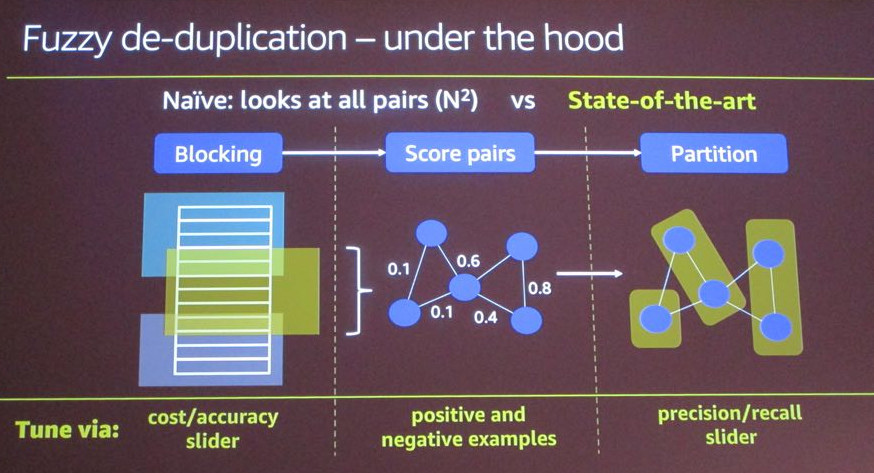
I managed a small, crack team of engineers as we turned our internal record linkage library into an external product offering. I led the engineering management and product definition, and worked closely with a senior Applied Scientist peer as we first pitched, then built, then launched, and finally maintained the GlueML service offering and its premier record linkage algorithm, FindMatches.
FindMatches distinguishes itself as one of the most performant record linkage solutions available today, both in terms of match quality and in terms of scalability and performance. On top of all that, we built an operationally sound service that never experienced a major event while I managed the team. GlueML and FindMatches was a triumph of both machine learning science and distributed systems engineering.
Bluefire Productions: VP of Engineering
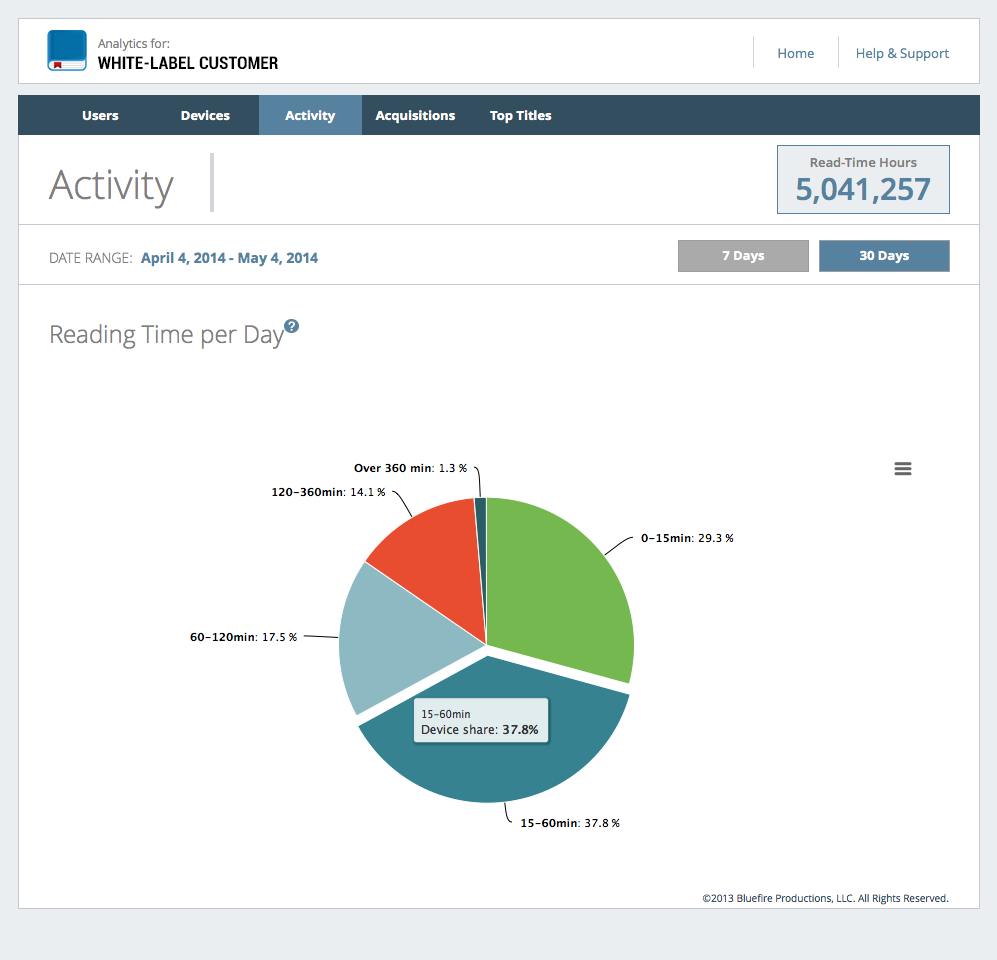
As VP and minority-owner of a small e-book focused tech company, my role was equal parts executive management and fullstack development lead.
Leadership: After Bluefire pivoted to eBooks, I became the third member (and co-owner) of Bluefire Productions. Executive leadership was close-knit and collaborative, and everyone was welcome to contribute to company strategy, product strategy, and engineering discussions. I helped to build up the company practices around hiring, quality assurance, and project management and took personal ownership of web development and backend services.
Full-stack development: In addition to my executive responsibilities, I was personally responsible for the majority of the web development and service engineering work at Bluefire. I led successful projects to deliver the Bluefire book location sync service to millions of Bluefire users (direct and indirect), as well as developing an automated web base eBook storefront that consumed OPDS feeds and turned them into web-based bookstores, as well as a data analysis pipeline that helped our customers analyze their customer usage in powerful ways.
Lilsoak Designs: Co-Founder

One of my most rewarding and least profitable projects. This project was a joint project with my wife that brought artisan goods from impoverished parts of the world, sold them in the United States, and returned all of the profits to the artisans themselves or to other fair trade and nonprofit organizations that worked closely with them.
While ultimately, we had to shut this project down in 2015, I remain immensely proud of the artisans we worked with, our dedicated, hard working partners, and the good we were able to do.
Papers, Posts and Talks
AWS Online Techtalk for GlueML & FindMatches Algorithm
Here's a quick talk I gave in 2019 running through the basics of how to use the brand new machine-learning functionality in AWS Glue that included a really top-tier record linkage algorithm in my completely biased opinion. This was the first time we publicly demoed the code that my team had been working towards for at least three years, and I'm still really proud of what we accomplished.
Intersection Dynamic Blocking Patent
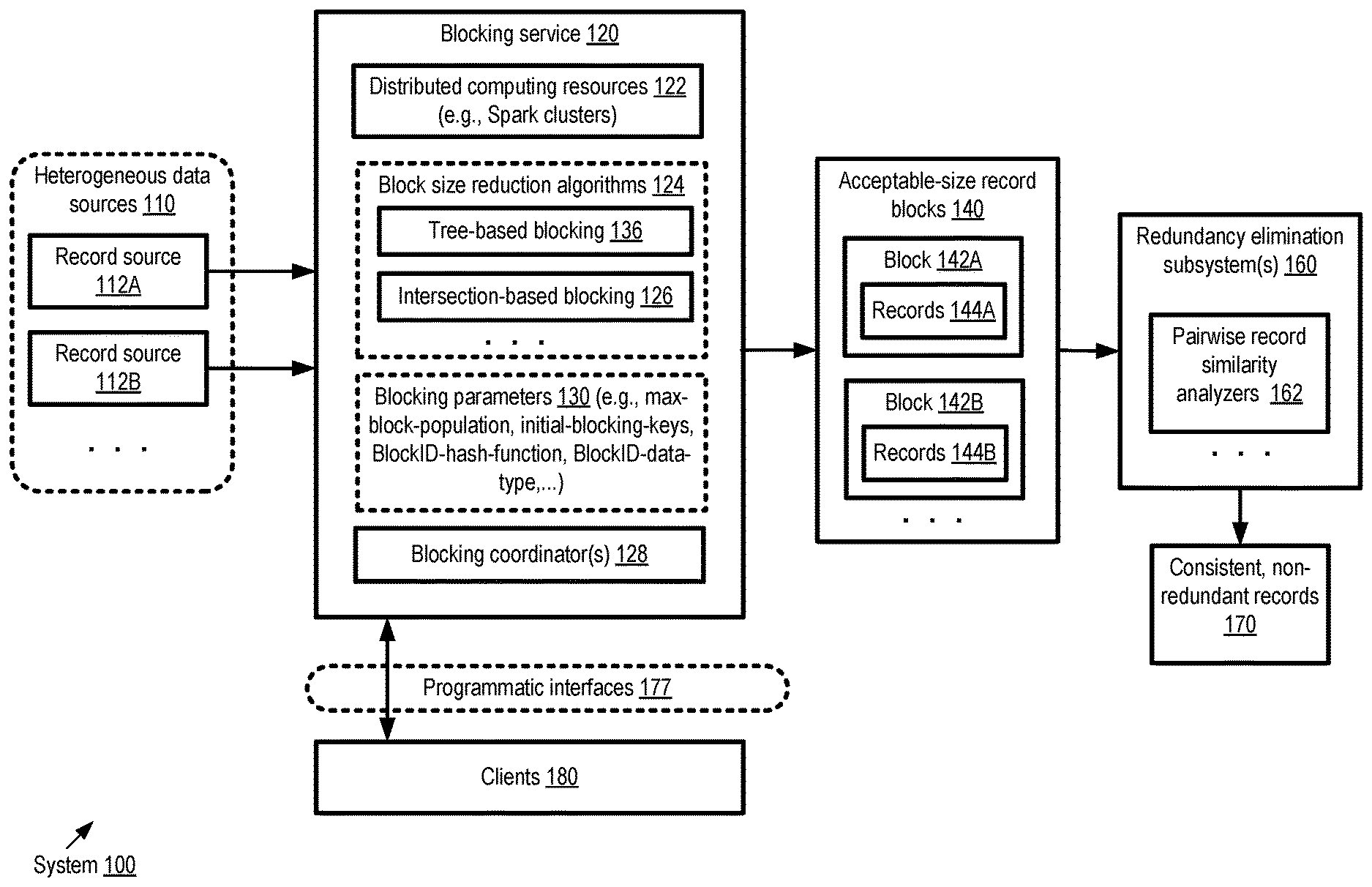
This patent describes some of the most impactful work I and my team at Amazon did. It describes a method that allowed our Spark-based record linkage to operated on a substantially larger scale (and sped things up to boot).
Auto-ML for Record Linkage Patent
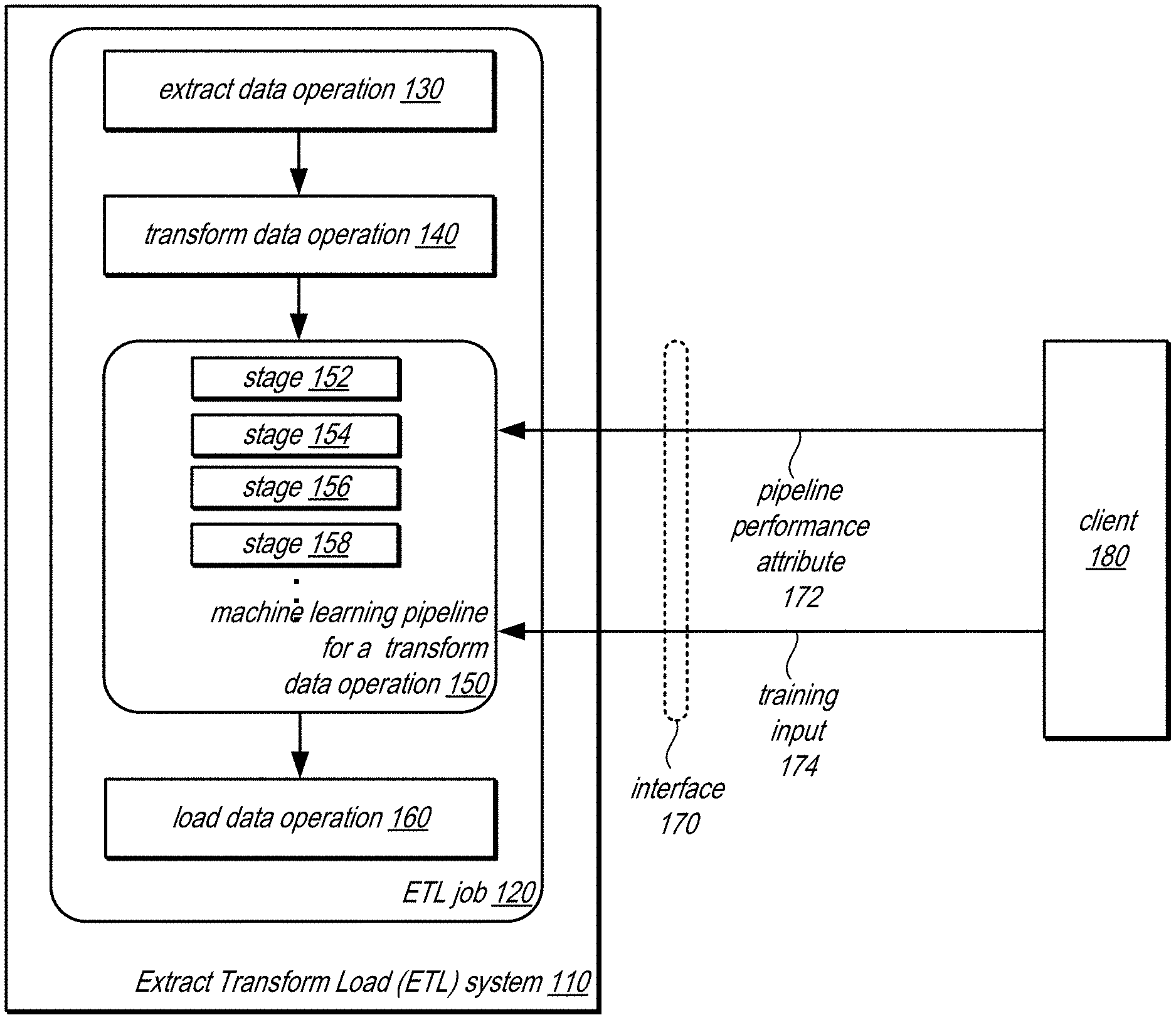
The AutoML for Record Linkage patent describes some of the innovations that the Glue ML team did to make it relatively simple to tune a record linkage system, such as FindMatches for AWS Glue, to individually unique scaling, precision, and recall requirements.
Paper: Scalable Blocking for Very Large Databases

Accepted ECML PKDD 2020 / DINA 2020
This paper describes some of the most impactful work I and my team at Amazon did. It describes a method that allowed our Spark-based record linkage to operated on a substantially larger scale (and sped things up to boot).
AWS Blog Post: Integrate and deduplicate datasets using AWS Lake Formation FindMatches
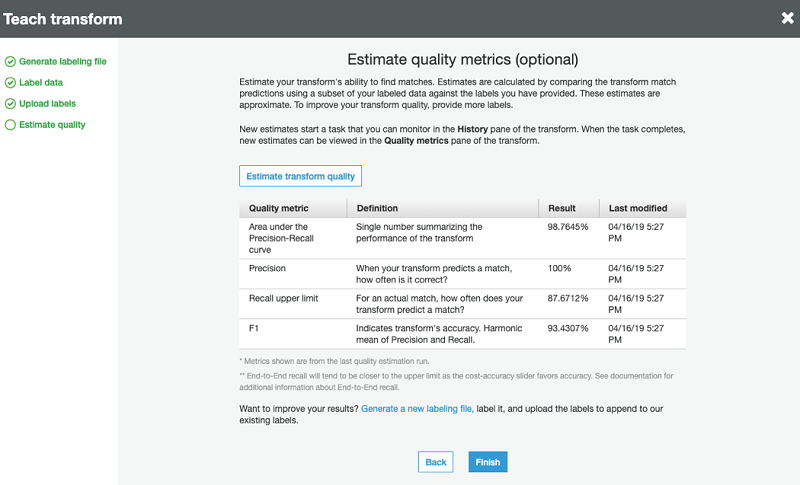
Integrate and deduplicate datasets using AWS Lake Formation FindMatches remains the best getting started guide that I know to using the FindMatches machine-learning based record matching algorithm. AWS continues to not charge extra for this algorithm, which means that it continues to be quite possibly the most inexpensive way to perform high-quality record linkage today. Definitely worth looking into if you have a matching problem involving non-canonical identifiers.